Java Stream流操作
前言
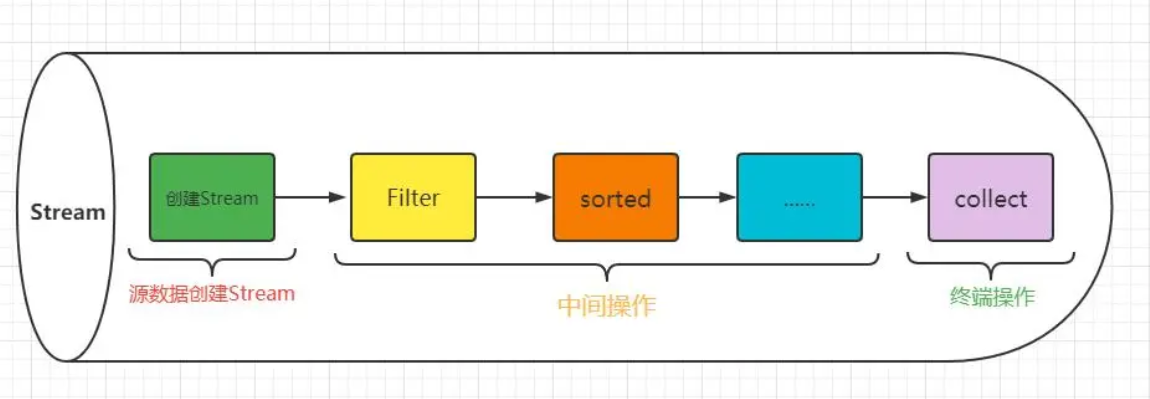
Stream流是从支持数据处理操作的源生成的元素序列,源可以是数组、文件、集合、函数。流不是集合元素,它不是数据结构并不保存数据,它的主要目的在于计算。
Stream流是对集合(Collection)对象功能的增强,与Lambda表达式结合,可以提高编程效率、间接性和程序可读性。
而且有句话说的好,如果会stream流,那么你和大数据就只隔了一层纱。所以对它的学习还是有必要的。
Stream流的特点
1、代码简洁:函数式编程写出的代码简洁且意图明确,使用stream接口让你从此告别for循环
2、多核友好:Java函数式编程使得编写并行程序如此简单,就是调用一下方法
流的创建
1.stream创建
1
| Stream<Integer> stream1 = Stream.of(1,2,3,4,5);
|
2.集合创建
1
2
3
4
5
6
7
| List<Integer> integerList = new ArrayList<>();
integerList.add(1);
integerList.add(2);
integerList.add(3);
integerList.add(4);
integerList.add(5);
Stream<Integer> listStream = integerList.stream();
|
3.数组创建
1
2
| int[] intArr = {1, 2, 3, 4, 5};
IntStream arrayStream = Arrays.stream(intArr);
|
4.文件创建
1
2
3
4
5
| try {
Stream<String> fileStream = Files.lines(Paths.get("data.txt"), Charset.defaultCharset());
} catch (IOException e) {
e.printStackTrace();
}
|
5.函数创建(iterator和generator)
iterator
1
| Stream<Integer> iterateStream = Stream.iterate(0, n -> n + 2).limit(5);
|
iterate方法接受两个参数,第一个为初始化值,第二个为进行的函数操作,因为iterator生成的流为无限流,通过limit方法对流进行了截断,只生成5个偶数
generator
1
2
3
4
5
| Stream<Integer> limit = Stream.generate(Math::random).limit(5).map(i->100*i).map(Double::intValue);
List<Integer> integerList = limit.collect(Collectors.toList());
for (Integer integer : integerList) {
System.out.println(integer);
}
|
generate方法接受一个参数,方法参数类型为Supplier ,由它为流提供值。generate生成的流也是无限流,因此通过limit对流进行了截断
中间操作符
直接上代码,假设有这么一个List集合:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public static void main(String[] args) {
List<User> userList = getUserList();
}
private static List<User> getUserList() {
List<User> userList = new ArrayList<>();
userList.add(new User(1,"张三",18,"上海"));
userList.add(new User(2,"王五",16,"上海"));
userList.add(new User(3,"李四",20,"上海"));
userList.add(new User(4,"张雷",22,"北京"));
userList.add(new User(5,"张超",15,"深圳"));
userList.add(new User(6,"李雷",24,"北京"));
userList.add(new User(7,"王爷",21,"上海"));
userList.add(new User(8,"张三丰",18,"广州"));
userList.add(new User(9,"赵六",16,"广州"));
userList.add(new User(10,"赵无极",26,"深圳"));
return userList;
}
|
filter过滤
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
List<User> filetrUserList = userList.stream()
.filter(user -> user.getId() > 6).collect(Collectors.toList());
filetrUserList.forEach(System.out::println);
List<String> mapUserList = userList.stream()
.map(user -> user.getName() + "用户").collect(Collectors.toList());
mapUserList.forEach(System.out::println);
List<String> distinctUsers = userList.stream().map(User::getCity).distinct()
.collect(Collectors.toList());
distinctUsers.forEach(System.out::println);
userList.stream().sorted(Comparator.comparing(User::getName).reversed())
.collect(Collectors.toList()).forEach(System.out::println);
userList.stream().limit(5).collect(Collectors.toList()).forEach(System.out::println);
userList.stream().skip(7).collect(Collectors.toList()).forEach(System.out::println);
userList.stream().flatMap(user -> Arrays.stream(user.getCity().split(",")))
.forEach(System.out::println);
userList.stream().peek(user -> user.setId(user.getId()+1)).forEach(System.out::println);
|
终端操作符
Stream流执行完终端操作之后,无法再执行其他动作,否则会报状态异常,提示该流已经被执行操作或者被关闭,想要再次执行操作必须重新创建Stream流
一个流有且只能有一个终端操作,当这个操作执行后,流就被关闭了,无法再被操作,因此一个流只能被遍历一次,若想在遍历需要通过源数据在生成流。
终端操作的执行,才会真正开始流的遍历。如 count、collect 等
★collect
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
Set set = userList.stream().collect(Collectors.toSet());
set.forEach(System.out::println);
System.out.println("--------------------------");
List list = userList.stream().collect(Collectors.toList());
list.forEach(System.out::println);
Map<String, User> cityToUserMap = userList.stream()
.collect(Collectors.toMap(User::getCity, user -> user, (u1, u2) -> u1));
String joinCity = userList.stream().map(User::getCity).collect(Collectors.joining("||"));
Map<String,List<User>> groupCity = userList.stream().collect(Collectors.groupingBy(User::getCity));
|
foreach
1
2
3
|
userList.stream().forEach(user -> System.out.println(user));
userList.stream().filter(user -> "上海".equals(user.getCity())).forEach(System.out::println);
|
findFirst、findAny
返回第一个元素、返回当前流中的任意元素
配合Optional类中的orElse
1
2
3
4
| User a = list.stream().filter(userT-> userT.getAge() == 12).findFirst().orElse(getMethod("a"));
User b = list.stream().filter(userT11-> userT11.getAge() == 12).findFirst().
orElseGet(()->getMethod("b"));
|
count、sum、min、max
类似SQL聚合函数
anyMatch、allMatch、noneMatch
检查是否至少匹配一个元素、检查是否匹配所有元素、检查是否没有匹配的元素。返回boolean
reduce
可以将流中元素反复结合起来,得到一个值
1
2
3
4
| List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> sum = numbers.stream()
.reduce((a, b) -> a + b);
sum.ifPresent(System.out::println);
|