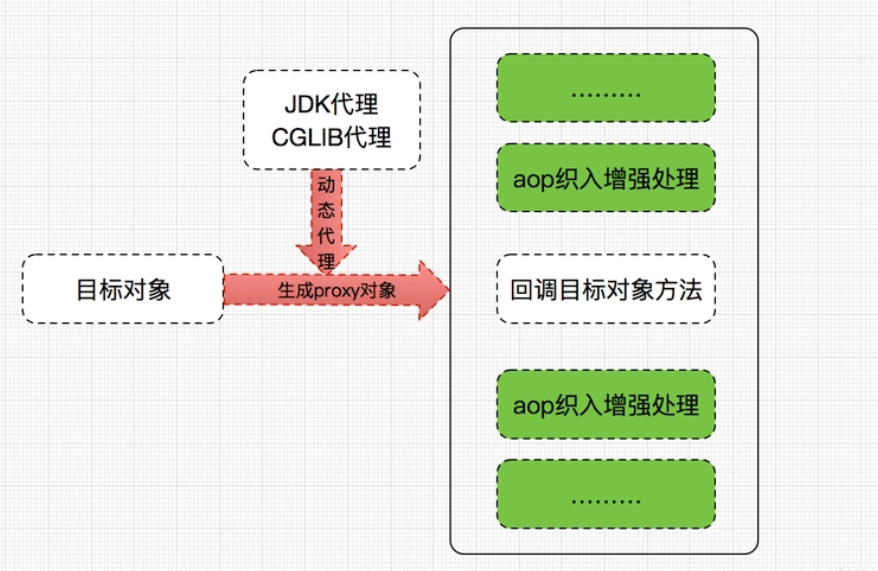
统计回文子串的数量
题目描述
题目来源:力扣 647
给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。
回文字符串 是正着读和倒过来读一样的字符串。
子字符串 是字符串中的由连续字符组成的一个序列。
具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。
示例 1:
1 | 输入:s = "abc" |
示例 2:
1 | 输入:s = "aaa" |
提示:
1 <= s.length <= 1000s由小写英文字母组成
方法
如果一上来用暴力写的话,必定超时,时间复杂度为O($n^3$)。超时的原因很简单,因为对于每一个子串我们都进行了遍历,这样会造成很多的重复计算。因此,我们需要考虑利用某些子串的判断结果来简化算法的复杂度。这里介绍动态规划和中心扩散两种方法。
动态规划
动规的解题步骤:
1.确定dp数组(dp table)以及下标的含义
布尔类型的dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串,如果是dp[i][j]为true,否则为false。
2.确定递推公式
在确定递推公式时,就要分析如下几种情况。
整体上是两种,就是s[i]与s[j]相等,s[i]与s[j]不相等这两种。
- 当s[i]与s[j]不相等,那没啥好说的了,dp[i][j]一定是false。
- 当s[i]与s[j]相等时,这就复杂一些了,有如下三种情况
- 情况一:下标i 与 j相同,同一个字符例如a,当然是回文子串
- 情况二:下标i 与 j相差为1,例如aa,也是文子串
- 情况三:下标:i 与 j相差大于1的时候,例如cabac,此时s[i]与s[j]已经相同了,我们看i到j区间是不是回文子串就看aba是不是回文就可以了,那么aba的区间就是 i+1 与 j-1区间,这个区间是不是回文就看
dp[i + 1][j - 1]是否为true。
以上三种情况分析完了,那么递归公式如下:
1 | if (s[i] == s[j]) { |
result就是统计回文子串的数量。
注意这里我没有列出当s[i]与s[j]不相等的时候,因为在下面dp[i][j]初始化的时候,就初始为false。
dp数组如何初始化
dp[i][j]可以初始化为true么? 当然不行,怎能刚开始就全都匹配上了。
所以dp[i][j]初始化为false。
确定遍历顺序
遍历顺序可有有点讲究了。
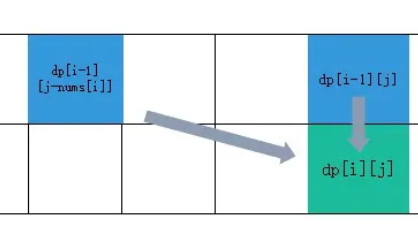
首先从递推公式中可以看出,情况三是根据dp[i + 1][j - 1]是否为true,在对dp[i][j]进行赋值true的。
dp[i + 1][j - 1]在 dp[i][j]的左下角,如图:
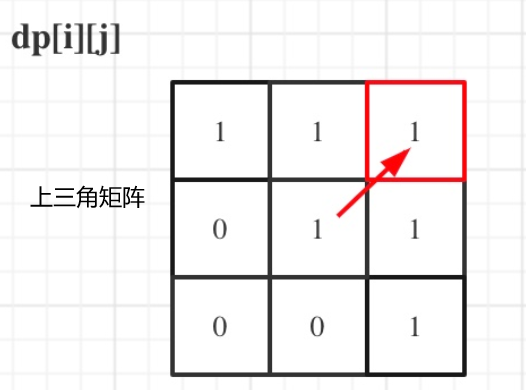
如果这矩阵是从上到下,从左到右遍历,那么会用到没有计算过的dp[i + 1][j - 1],也就是根据不确定是不是回文的区间[i+1,j-1],来判断了[i,j]是不是回文,那结果一定是不对的。
所以一定要从下到上,从左到右遍历,这样保证dp[i + 1][j - 1]都是经过计算的。
有的代码实现是优先遍历列,然后遍历行,其实也是一个道理,都是为了保证dp[i + 1][j - 1]都是经过计算的。
C++代码如下:
1 | class Solution { |
dp矩阵的压缩
可以看到,上面这种方法用到的dp矩阵是二维的,空间复杂度比较高。有没有一种办法来降低空间复杂度呢?答案是可以的。使用压缩矩阵的思路。
压缩二维矩阵的适用条件:当这一层(列)的结果仅依赖于上一层(列)时,那么可以在这一层(列)进行原地更新。
观察上面这个状态转移方程,我们知道,矩阵是从下网上遍历的,第i层的结果依赖于第i+1层,因此我们可以将矩阵进行纵向压缩。
遍历的顺序:必须是从下往上,从右往左。为什么必须是从右往左,而上面就可以从左往右呢?那是因为压缩后dp[j]依赖原来的dp[j-1],如果从左往右的话,原来的dp[j-1]就会被新的给覆盖掉。
C++代码如下:
1 | class Solution { |
中心扩散
首先确定回文串,就是找中心然后想两边扩散看是不是对称的就可以了。
在遍历中心点的时候,要注意中心点有两种情况。
一个元素可以作为中心点,两个元素也可以作为中心点。
对于三个元素,可以由一个元素左右添加元素得到,四个元素则可以由两个元素左右添加元素得到,所以我们在计算的时候,要注意一个元素为中心点和两个元素为中心点的情况。
C++代码如下:
1 | class Solution { |
以上两种方法对应的时间复杂度都是$O(n^2)$。
两种方法参考了代码随想录大佬的思路,链接:https://leetcode.cn/problems/palindromic-substrings/solutions/917242/dai-ma-sui-xiang-lu-dai-ni-xue-tou-dpzi-vidge/。