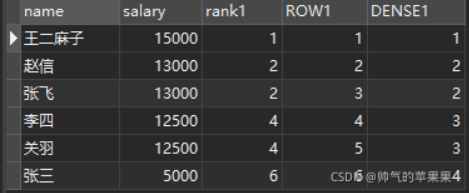
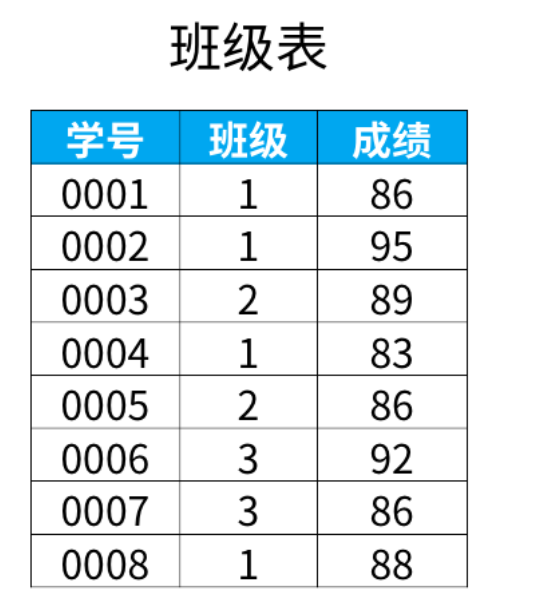
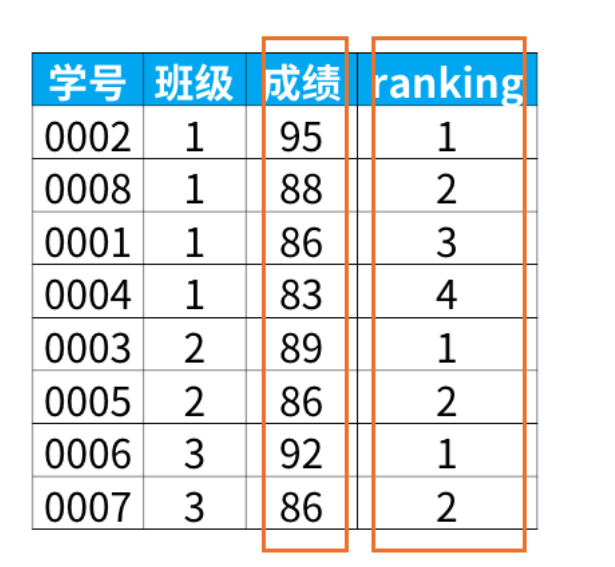
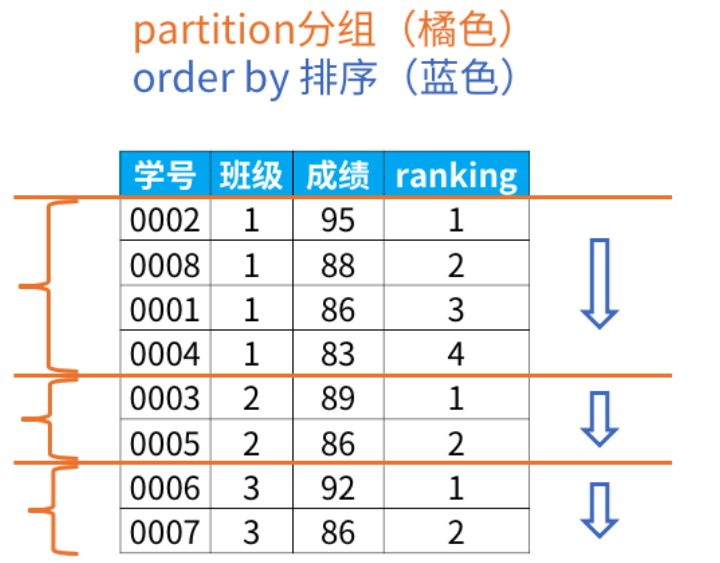
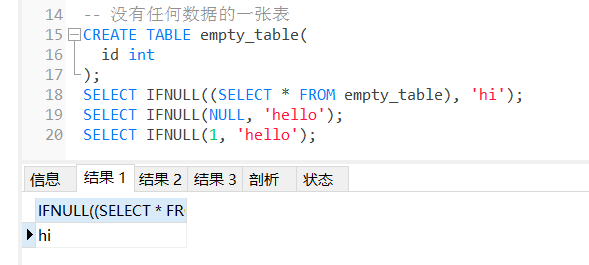
当我们只关心数据表有多少记录行而不需要知道具体的字段值时,类似select 1 from tbl是一个很不错的SQL语句。它通常用于子查询。这样可以减少系统开销,提高运行效率,因为这样子写的SQL语句,数据库引擎就不会去检索数据表里一条条具体的记录和每条记录里一个个具体的字段值并将它们放到内存里,而是根据查询到有多少行存在就输出多少个“1”,每个“1”代表有1行记录,同时选用数字1还因为它所占用的内存空间最小,当然用数字0的效果也一样。在不需要知道具体的记录值是什么的情况下这种写法无疑更加可取。
举个例子,统计每个班的学生人数
常规写法:select class,count (*) as pax from students group by class; 更优写法:select class,count (1) as pax from students group by class;
再比如,列出每个班最年轻的学生资料
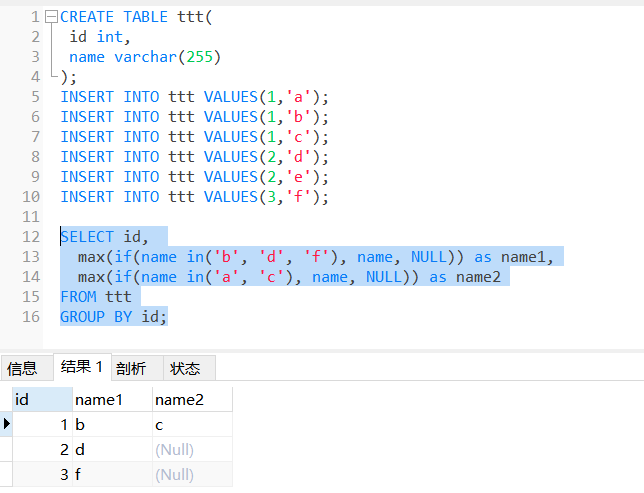
常规写法:
1 2
select a.*from students a wherenotexists(select b.sid from students b where b.sid != a.sid and b.date_birth > a.date_birth);
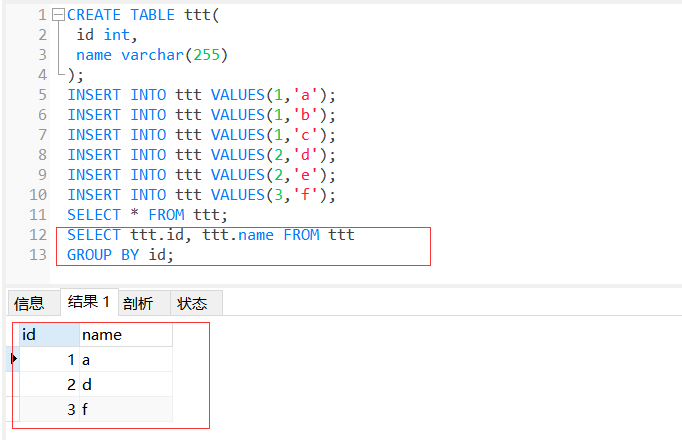
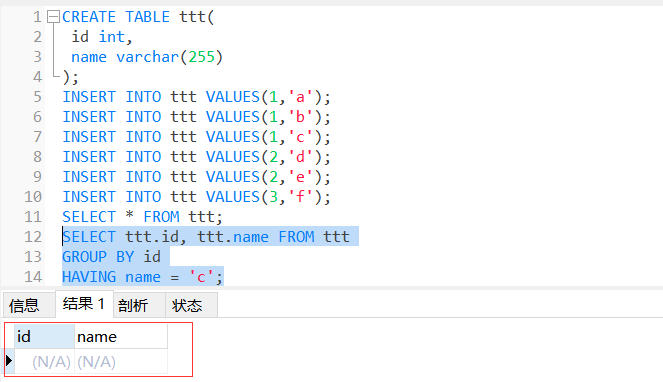
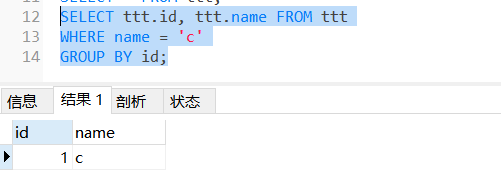
+--------+---------+ | id | name | +--------+---------+ | | a | | 1 | b | | | c | +--------+---------+ | 2 | d | | | e | +--------+---------+ | 3 | f | +--------+---------+
但是,由于一个单元格只能有一个值,所以最终的结果变成了这样:
1 2 3 4 5 6 7 8 9
+--------+---------+ | id | name | +--------+---------+ |1| a | +--------+---------+ |2| d | +--------+---------+ |3| f | +--------+---------+
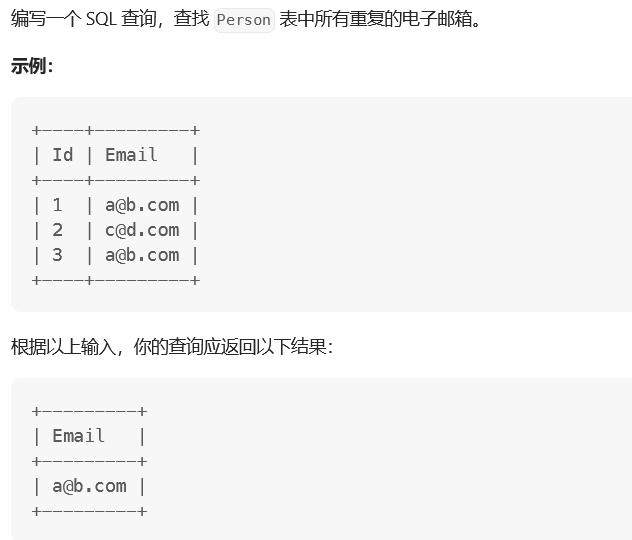
selectdistinct p1.Email as Email from Person as p1, Person as p2 where p1.Email = p2.Email and p1.Id != p2.Id;
要注意,distinct关键字必须加
法2:group by + having
1 2 3 4
select Email from person groupby Email havingcount(Email) >1;
法3:group by + 临时表
1 2 3 4 5 6 7
select Email from ( select Email, count(Email) as num from Person groupby Email ) as statistic where num >1;
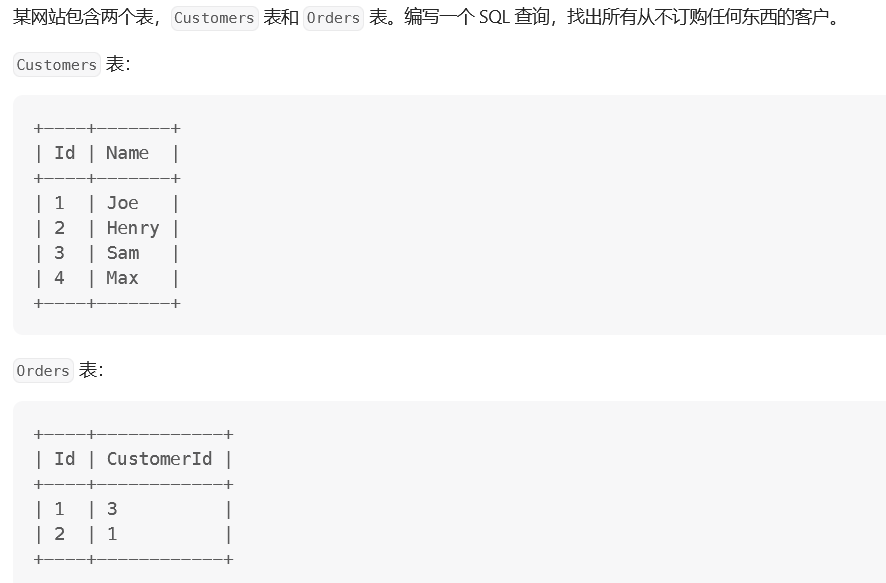
183 从不订购的客户
法1:子查询+判断是否为null
1 2 3 4 5 6 7 8 9
# Write your MySQL query statement below select statistic.name as Customers from ( select customers.name, orders.id as orders_id from customers leftjoin orders on customers.id = orders.Customerid ) as statistic where statistic.orders_id isnull;
这里有个坑,不能用value == null,而是得用value is null
法2:子查询+not in
1 2 3 4 5 6
select customers.name as'Customers' from customers where customers.id notin ( select customerid from orders );
196. 删除重复的电子邮箱
法1:子查询+not in
首先进行group by 对email去重,并保留最小的id,得到id列表, 然后删除不在这个列表中的数据
1 2 3 4
deletefrom Person where id notin ( selectmin(id) as id from Person groupby Email );
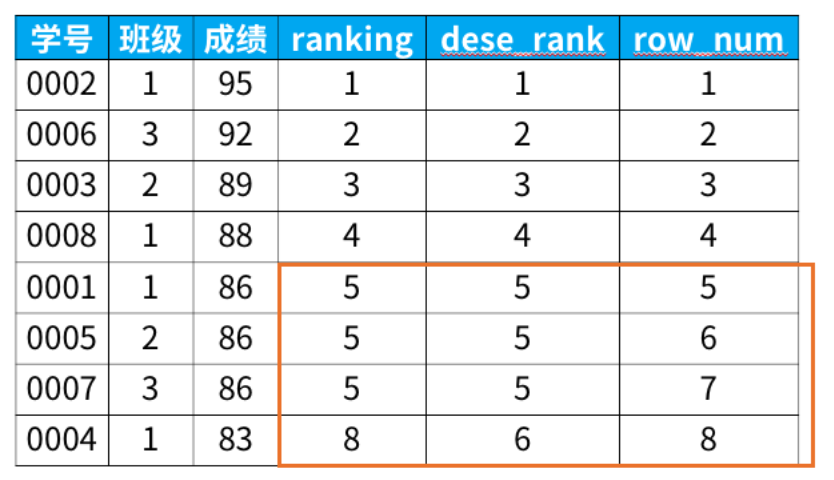
select *, rank() over (order by 成绩 desc) as ranking, dense_rank() over (order by 成绩 desc) as dese_rank, row_number() over (order by 成绩 desc) as row_num from 班级表
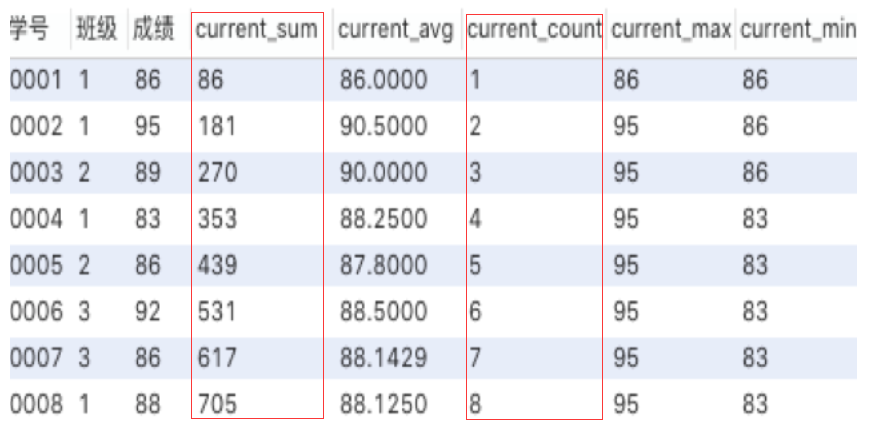
select *, sum(成绩) over (order by 学号) as current_sum, avg(成绩) over (order by 学号) as current_avg, count(成绩) over (order by 学号) as current_count, max(成绩) over (order by 学号) as current_max, min(成绩) over (order by 学号) as current_min from 班级表
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | recordDate | date | | temperature | int | +---------------+---------+ id 是这个表的主键 该表包含特定日期的温度信息
# Write your MySQL query statement below # 题解一 SELECT customer_number FROM ( SELECT customer_number, COUNT(customer_number) AS n FROM Orders GROUPBY customer_number ) T ORDERBY n DESC LIMIT 1;
select ifnull(( selectdistinct salary from Employee orderby salary desc limit 1,1 ), NULL ) as SecondHighestSalary ;
法2:
1 2 3 4 5 6 7 8 9
select ifnull(( selectmax(distinct salary) from Employee where salary < ( selectmax(distinct salary) from Employee ) ), NULL ) as SecondHighestSalary ;
先用where把最大的那个薪资筛掉,然后再在剩下的薪资里选择最大的
607.销售员
表: SalesPerson
1 2 3 4 5 6 7 8 9 10 11
+-----------------+---------+ | Column Name | Type | +-----------------+---------+ | sales_id | int | | name | varchar | | salary | int | | commission_rate | int | | hire_date | date | +-----------------+---------+ sales_id 是该表的主键列。 该表的每一行都显示了销售人员的姓名和 ID ,以及他们的工资、佣金率和雇佣日期。
表: Company
1 2 3 4 5 6 7 8 9
+-------------+---------+ | Column Name | Type | +-------------+---------+ | com_id | int | | name | varchar | | city | varchar | +-------------+---------+ com_id 是该表的主键列。 该表的每一行都表示公司的名称和 ID ,以及公司所在的城市。
表: Orders
1 2 3 4 5 6 7 8 9 10 11 12 13
+-------------+------+ | Column Name | Type | +-------------+------+ | order_id | int | | order_date | date | | com_id | int | | sales_id | int | | amount | int | +-------------+------+ order_id 是该表的主键列。 com_id 是 Company 表中 com_id 的外键。 sales_id 是来自销售员表 sales_id 的外键。 该表的每一行包含一个订单的信息。这包括公司的 ID 、销售人员的 ID 、订单日期和支付的金额。
selectdistinct salesperson.name from orders leftjoin salesperson on salesperson.sales_id = orders.sales_id leftjoin company on company.com_id = orders.com_id where company.name !='RED';
# Write your MySQL query statement below selectdistinct SalesPerson.name as name from SalesPerson where name notin ( select SalesPerson.name from orders leftjoin salesperson on salesperson.sales_id = orders.sales_id leftjoin company on company.com_id = orders.com_id where company.name ='RED' );
627.变更性别
Salary 表:
1 2 3 4 5 6 7 8 9 10 11
+-------------+----------+ | Column Name | Type | +-------------+----------+ | id | int | | name | varchar | | sex | ENUM | | salary | int | +-------------+----------+ id 是这个表的主键。 sex 这一列的值是 ENUM 类型,只能从 ('m', 'f') 中取。 本表包含公司雇员的信息。
SELECTDISTINCT Num as ConsecutiveNums FROM ( SELECT Num,COUNT(1) as SerialCount FROM ( SELECT Id,Num, row_number() over(orderby id) -ROW_NUMBER() over(partitionby Num orderby Id) as SerialNumberSubGroup FROM Logs ) as Sub GROUPBY Num,SerialNumberSubGroup HAVINGCOUNT(1) >=3 ) asResult;
SerialNumberSubGroup:通过row_number() over(order by id)和ROW_NUMBER() over(partition by Num order by Id)进行相减得到,若连续三次相同,那么就说明同一个数字出现了三次以上。