NIO三大组件
NIO三大组件
简单介绍
Channel与Buffer
Java NIO系统的核心在于:通道(Channel)和缓冲区(Buffer)。通道表示打开到 IO 设备(例如:文件、套接字)的连接。若需要使用 NIO 系统,需要获取用于连接 IO 设备的通道以及用于容纳数据的缓冲区。然后操作缓冲区,对数据进行处理
简而言之,通道负责传输,缓冲区负责存储
常见的Channel有以下四种,其中FileChannel主要用于文件传输,其余三种用于网络通信
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
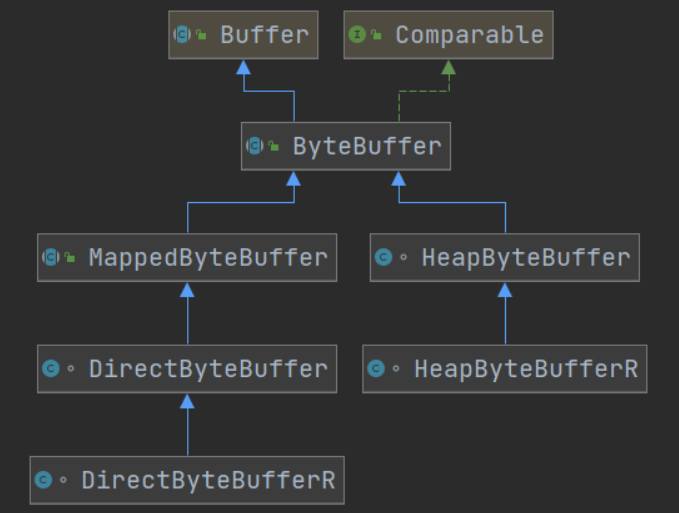
Buffer有以下几种,其中使用较多的是ByteBuffer
- ByteBuffer
- MappedByteBuffer
- DirectByteBuffer
- HeapByteBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
- CharBuffer
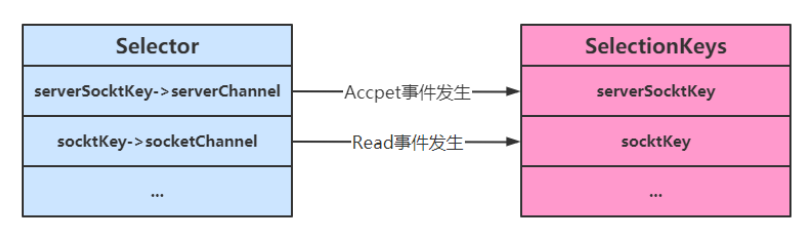
1、Selector
在使用Selector之前,处理socket连接还有以下两种方法
使用多线程技术
为每个连接分别开辟一个线程,分别去处理对应的socket连接
这种方法存在以下几个问题
- 内存占用高
- 每个线程都需要占用一定的内存,当连接较多时,会开辟大量线程,导致占用大量内存,容易堆溢出
- 线程上下文切换成本高
- 只适合连接数少的场景
- 连接数过多,会导致创建很多线程,从而出现问题
使用线程池技术
使用线程池,让线程池中的线程去处理连接
这种方法存在以下几个问题
阻塞模式下,线程仅能处理一个连接
- 线程池中的线程获取任务(task)后,只有当其执行完任务之后(断开连接后),才会去获取并执行下一个任务
- 若socket连接一直未断开,则其对应的线程无法处理其他socket连接
仅适合
短连接
场景
- 短连接即建立连接发送请求并响应后就立即断开,使得线程池中的线程可以快速处理其他连接
使用选择器
selector 的作用就是配合一个线程来管理多个 channel(fileChannel因为是阻塞式的,所以无法使用selector),获取这些 channel 上发生的事件,这些 channel 工作在非阻塞模式下,当一个channel中没有执行任务时,可以去执行其他channel中的任务。适合连接数多,但流量较少的场景
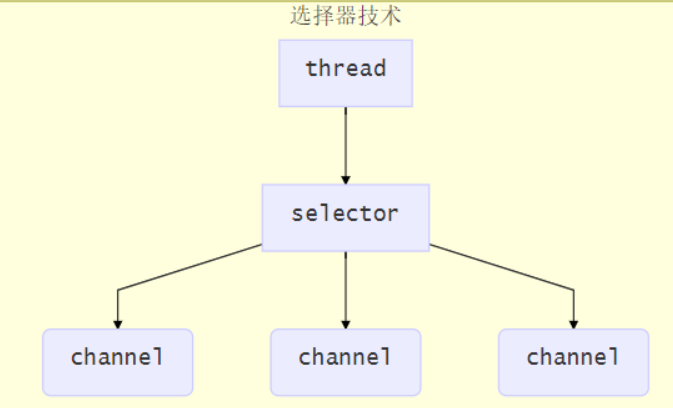
若事件未就绪,调用 selector 的 select() 方法会阻塞线程,直到 channel 发生了就绪事件。这些事件就绪后,select 方法就会返回这些事件交给 thread 来处理
2、Buffer
创建方式
1 | ByteBuffer buffer = ByteBuffer.allocate(1024); |
allocate()方法分配的 ByteBuffer 对象对于 JVM 来说是更加友好的,可以轻松地进行垃圾回收,但在读写时需要进行数据拷贝。allocateDirect()方法分配的 ByteBuffer 对象对于底层操作系统来说是更加友好的,可以直接访问底层内存,提高读写性能,但不易进行垃圾回收。
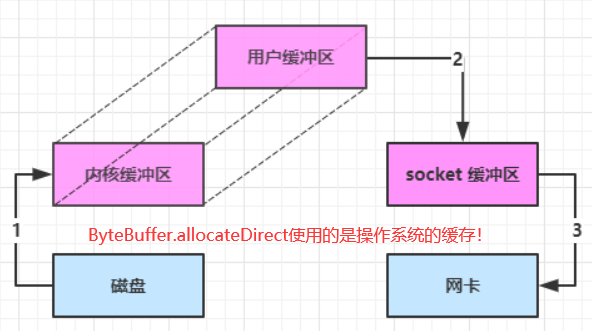
两者的使用场景
allocate()方法适用于频繁的读写操作,数据量较小,并且对 GC 影响较小的情况。allocateDirect()方法适用于需要高性能、大量读写、数据传输等场景,例如网络编程、文件操作等。
下面这种方式也是可以的。
1 | ByteBuffer buffer = StandardCharsets.UTF_8.encode(str); |
使用方式
- 向 channel 写入数据,例如调用 channel.read(buffer)
- 调用 flip() 切换至读模式
- flip会使得buffer中的limit变为position,position变为0
- 从 buffer 读取数据,例如调用 buffer.get()
- 调用 clear() 或者compact()切换至写模式
- 调用clear()方法时position=0,limit变为capacity
- 调用compact()方法时,会将缓冲区中的未读数据压缩到缓冲区前面
- 重复以上步骤
使用ByteBuffer读取文件中的内容
1 | public class TestByteBuffer { |
核心属性
字节缓冲区的父类Buffer中有几个核心属性,如下
1 | // Invariants: mark <= position <= limit <= capacity |
- capacity:缓冲区的容量。通过构造函数赋予,一旦设置,无法更改
- limit:缓冲区的界限。位于limit 后的数据不可读写。缓冲区的限制不能为负,并且不能大于其容量
- position:下一个读写位置的索引。缓冲区的位置不能为负,并且不能大于limit
- mark:记录当前position的值。position被改变后,可以通过调用reset() 方法恢复到mark的位置
以上四个属性必须满足以下要求
mark <= position <= limit <= capacity
核心方法
put()方法
- put()方法可以将一个数据放入到缓冲区中。
- 进行该操作后,postition的值会+1,指向下一个可以放入的位置。capacity = limit ,为缓冲区容量的值。
flip()方法
- flip()方法会切换对缓冲区的操作模式,由写->读 / 读->写
- 进行该操作后
- 如果是写模式->读模式,position = 0 , limit 指向最后一个元素的下一个位置,capacity不变
- 如果是读->写,则恢复为put()方法中的值
get()方法
- get()方法会读取缓冲区中的一个值
- 进行该操作后,position会+1,如果超过了limit则会抛出异常
- 注意:get(i)方法不会改变position的值
1 | ByteBuffer buffer = ByteBuffer.allocate(5); |
rewind()方法
- 该方法只能在读模式下使用
- rewind()方法后,会恢复position、limit和capacity的值,变为进行get()前的值
1 | ByteBuffer buffer = ByteBuffer.allocate(5); |
clean()方法
- clean()方法会将缓冲区中的各个属性恢复为最初的状态,position = 0, capacity = limit
- 此时缓冲区的数据依然存在,处于“被遗忘”状态,下次进行写操作时会覆盖这些数据
mark()和reset()方法
- mark()方法会将postion的值保存到mark属性中
- reset()方法会将position的值改为mark中保存的值
compact()方法
此方法为ByteBuffer的方法,而不是Buffer的方法
- compact会把未读完的数据向前压缩,然后切换到写模式
- 数据前移后,原位置的值并未清零,写时会覆盖之前的值
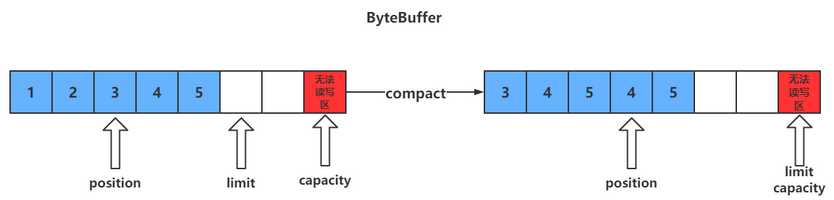
clear() VS compact()
clear只是对position、limit、mark进行重置,而compact在对position进行设置,以及limit、mark进行重置的同时,还涉及到数据在内存中拷贝(会调用arraycopy)。所以compact比clear更耗性能。但compact能保存你未读取的数据,将新数据追加到为读取的数据之后;而clear则不行,若你调用了clear,则未读取的数据就无法再读取到了
所以需要根据情况来判断使用哪种方法进行模式切换
粘包与半包
粘包指的是多个数据包被一次性接收或发送,导致多个数据包粘在一起形成一个大的数据包。半包则是指一个数据包被分割成多个小的数据包进行接收或发送。
现象
网络上有多条数据发送给服务端,数据之间使用 \n 进行分隔
但由于某种原因这些数据在接收时,被进行了重新组合,例如原始数据有3条为
- Hello,world\n
- I’m Nyima\n
- How are you?\n
变成了下面的两个 byteBuffer (粘包,半包)
- Hello,world\nI’m Nyima\nHo
- w are you?\n
出现原因
粘包
发送方在发送数据时,并不是一条一条地发送数据,而是将数据整合在一起,当数据达到一定的数量后再一起发送。这就会导致多条信息被放在一个缓冲区中被一起发送出去
半包
接收方的缓冲区的大小是有限的,当接收方的缓冲区满了以后,就需要将信息截断,等缓冲区空了以后再继续放入数据。这就会发生一段完整的数据最后被截断的现象
解决办法
1.分隔符处理法
通过get(index)方法遍历ByteBuffer,遇到分隔符时进行处理。
注意:get(index)不会改变position的值
- 记录该段数据长度,以便于申请对应大小的缓冲区
- 将缓冲区的数据通过get()方法写入到target中
调用compact方法切换模式,因为缓冲区中可能还有未读的数据
1 | public class ByteBufferDemo { |
2.消息长度标识
在这儿就不用代码举例子了,比如HTTP响应报文,会专门有一个头用来标识报文长度。
3、Channel
这里用FileChannel来举例。
工作模式
FileChannel只能在阻塞模式下工作,所以无法搭配Selector
获取
不能直接打开 FileChannel,必须通过 FileInputStream、FileOutputStream 或者 RandomAccessFile 来获取 FileChannel,它们都有 getChannel 方法
- 通过 FileInputStream 获取的 channel 只能读
- 通过 FileOutputStream 获取的 channel 只能写
- 通过 RandomAccessFile 是否能读写根据构造 RandomAccessFile 时的读写模式决定(与普通的输入流(如
FileInputStream)和输出流(如FileOutputStream)不同,RandomAccessFile允许在文件中定位并读取或写入任意位置的数据)
读取
通过 FileInputStream 获取channel,通过read方法将数据写入到ByteBuffer中
read方法的返回值表示读到了多少字节,若读到了文件末尾则返回-1
1 | int readBytes = channel.read(buffer); |
可根据返回值判断是否读取完毕
1 | while(channel.read(buffer) > 0) { |
写入
因为buffer也是有大小的,所以 write 方法并不能保证一次将 buffer 中的内容全部写入 channel。必须需要按照以下规则进行写入
1 | // 通过hasRemaining()方法查看缓冲区中是否还有数据未写入到通道中 |
关闭
通道需要close,一般情况通过try-with-resource进行关闭,最好使用以下方法获取stream以及channel,避免某些原因使得资源未被关闭
1 | public class TestChannel { |
文件空洞
空洞(Sparse Hole)是指文件中已分配但未写入数据的区域。在文件系统中,文件通常由一系列的数据块(或簇)组成,每个数据块存储特定大小的数据。当我们在文件中创建一个空洞时,文件系统会为该空洞保留相应的块或簇,但实际上并不将任何数据写入这些块或簇。
具体来说,空洞是在逻辑上而非物理上存在的。文件系统记录文件的大小和所占用的磁盘空间,但并不将空洞部分实际写入到磁盘。在读取文件时,如果读取到空洞部分,文件系统会返回空数据(通常用零填充)。因此,在文件中存在空洞时,读取操作会返回零值或空数据。
空洞的存在可以带来一些优势。首先,它可以减少磁盘空间的使用,因为没有数据的空洞并不占用实际的磁盘空间。其次,它可以提高文件的创建和扩展速度,因为创建空洞只需要修改文件的元数据,而无需实际写入大量的数据。
然而,需要注意的是,在某些情况下,空洞可能会导致不可预测的行为或资源浪费。例如,当备份或复制文件时,某些工具可能会将空洞部分误认为是实际数据而占用存储空间。另外,某些应用程序可能无法正确处理包含空洞的文件。
总之,空洞指的是在文件中已分配但未写入数据的区域。文件系统会保留这些空洞的位置信息,但不会实际写入数据。了解空洞的概念可以帮助我们更好地理解文件系统的工作原理,并在必要时避免产生不必要的空洞或处理相关问题。
位置
position
channel也拥有一个保存读取数据位置的属性,即position
1 | long pos = channel.position(); |
可以通过position(int pos)设置channel中position的值
1 | long newPos = ...; |
设置当前位置时,如果设置为文件的末尾
- 如果你尝试从该位置读取数据,将会返回 -1。这是因为已经到达了文件的末尾,无法读取更多的数据
- 这时写入,会追加内容。需要注意的是,如果当前位置超过了文件的末尾,意味着在新内容和原末尾之间会存在一个空洞
写文件示例:
1 | try (RandomAccessFile file = new RandomAccessFile("F://测试文本.txt", "rw")) { |
强制写入
操作系统出于性能的考虑,会将数据缓存,不是立刻写入磁盘,而是等到缓存满了以后将所有数据一次性的写入磁盘。可以调用 force(true) 方法将文件内容和元数据(文件的权限等信息)立刻写入磁盘。需要注意的是,调用 force(true) 方法可能会对性能产生一定的影响,因为它强制操作系统将数据写入磁盘的频率更高。因此,在实际应用中,应根据具体的需求和性能要求来决定是否调用 force(true) 方法。
两个Channel传输数据(零拷贝)
transferTo方法
使用transferTo方法可以快速、高效地将一个channel中的数据传输到另一个channel中,但一次只能传输2G的内容
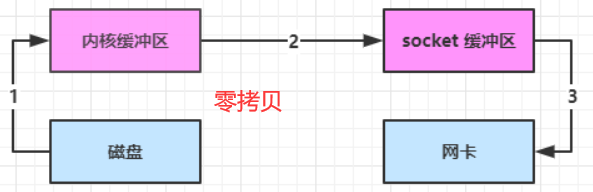
transferTo底层使用了零拷贝技术。传统的文件传输,需要先将文件拷贝到内核,内核再拷贝到用户空间,执行两次拷贝操作。而零拷贝直接在内核空间完成文件传输,数据无需拷贝到 JVM 内存中,避免了数据在用户空间和内核空间之间的复制。传统的IO操作大概有四步,如图所示:
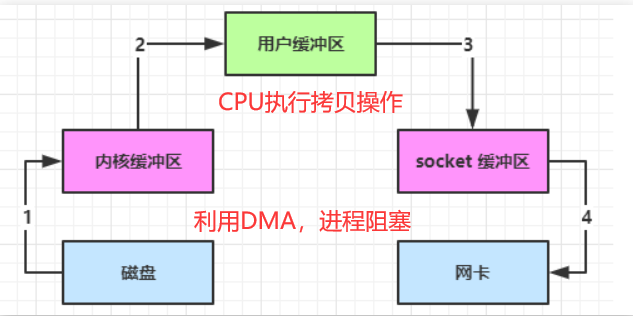
看一下零拷贝的过程。对于用户来说,不需要再去新建缓冲区来执行冗余的拷贝操作。
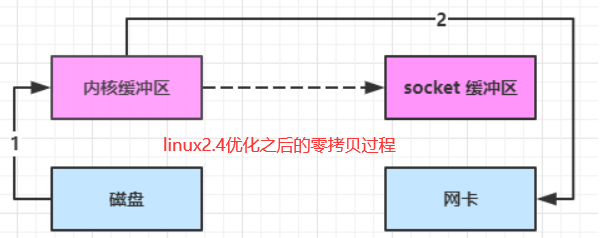
transferTo方法代码演示如下:
1 | public class TestChannel { |
当传输的文件大于2G时,需要使用以下方法进行多次传输
1 | public class TestChannel { |
当然上面的transferTo只是其中一种零拷贝技术,此外还有DMA和内存映射两种技术。